
What type of database is best?
Once upon a time, if you needed a database, most of us would have reached for Excel or perhaps Microsoft Access, or for larger requirements, MS SQL or Oracle. Today, there are many more choices which, depending on the type of data you want to store, all have advantages and benefits. In this post, we’ll explore the different options and benefits of different database types SQL vs NoSQL..
Whether it’s a business CRM system, a student management system or a research project, at some stage, you will need a database to hold all the necessary information. Generally, you will automatically lean towards the database tool you’ve used in the past, which is fine if the data type is the same or performance is not an important requirement for your new system.
Choosing the wrong database may not only cause performance issues or restrictions from the outset, but when the project grows it will certainly become an issue, whether problems are caused by the amount of data held, type of data, integration with other system, or the number of users required to access the data having the right platform helps to address them. These are just a few examples that need consideration.
Even if you are working with a mature database, it’s important to know it’s limitations and identify opportunities possible by changing or adding different types of database tools (SQL vs NoSQL) to your systems for different data types.
This post explores the 2 main approaches to databases:
-
- Relational Databases (SQL based).
- NoSQL Databases. We will go over the different types of NoSQL tools and when to use each one.
It will review some of the advantages and disadvantages of each.

Relational DBs (SQL based)
Relational databases consist of a collection of tables (similar to Excel sheets), that are connected via UUID (universally unique identifiers). Each row in a table represents a record. Why is it called relational? Let’s say you have a table of student information, consisting of names, addresses, ID’s, course grades etc.. Every separate item of data has a relationship with the others as shown in the diagram below, where the value in the ‘Student ID’ column points to rows in the ‘Students’ table by the value of their ‘ID’ column.

All relational databases are queried with SQL-type languages, which are commonly used and allow the indexing of columns for faster queries.
Because of its structured nature, the relational database’s schema is decided long before adding of any data.
Common relational databases include MySQL, PostgreSQL, Oracle, MS SQL Server
NoSQL Databases
In relational databases as we have seen, everything is structured into rows and columns. In NoSQL databases there is no common structured schema for the records. Most NoSQL databases hold JSON records; and different records can include different fields.
NoSQL databases also support querying using SQL, but using it is not the best practice for them.
There are 4 main types of NoSQL databases:
- Document-oriented Databases
Unlike Relational databases, the base unit of document oriented NoSQL databases is a document unit. Each document is a JSON and the schema may vary between different documents and contain different fields.
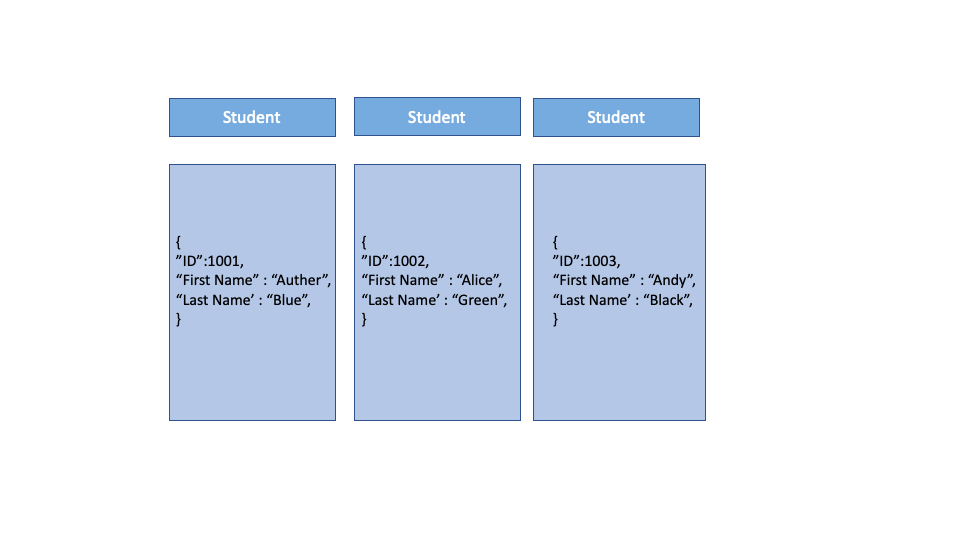
Document Databases allow indexing of some fields in the document to allow faster queries based on those fields but would require all the documents to contain the same field.
Document oriented databases are perfect for data analysis. Since different records are not dependent on one another (logic and structure-wise) they are ideal for parallel computations as the lack of dependence allows you to perform big data analytics easily.
Common document-based databases: MongoDB, CouchDB, DocumentDB.
- Columnar Databases
The base unit of this type of database is a column in the table, meaning the data is stored column by column. It makes column-based queries very efficient, and since the data on each column is similar, it allows better compression of the data.
Columnar databases are best used when you usually query your data on a subset of columns in your data. Columnar databases perform such queries very fast since it only needs to read these specific columns (while row-based DB would have to read the entire data). This is often common in data science, where each column represents a feature. It is also common when storing and querying logs from other equipment. Often a lot more fields are stored in log databases than are queried each time.
Common column DB database: Cassandra
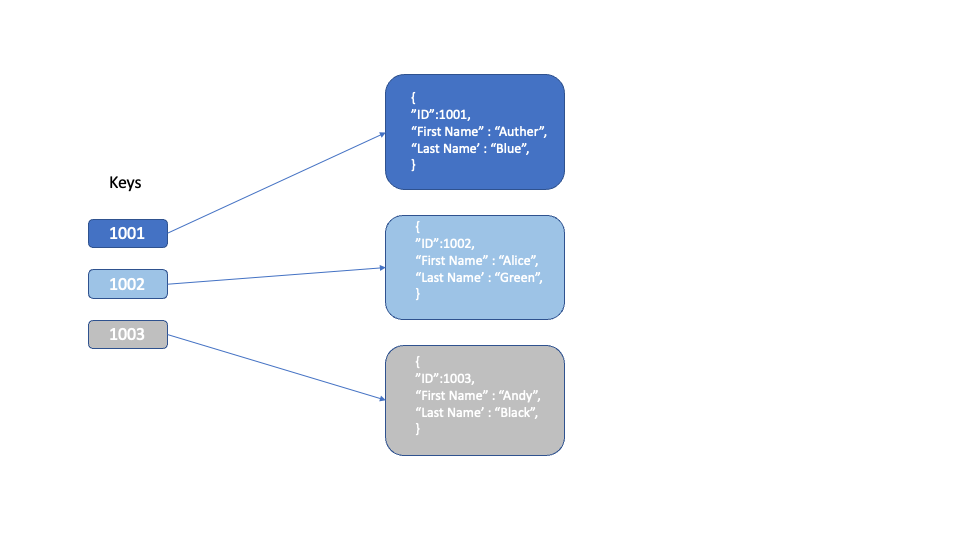
- Key-value Databases
Where queries are key based only, i.e. the query is a specific key and it returns the value for that key. Key value databases do not support queries across different record values such as ‘select all records where First name = Alice’
One of the advantages of key value databases is that it is very fast, because of the use of unique keys, and most of key-value databases store data in RAM, which allows quick access.
Disadvantages are that you need to define unique keys that are good identifiers and build them into the data at the time of the query.
It can also be more expensive that other types of databases due to the greater use of relatively expensive RAM.
Mainly used for short term information such as a cache since it is very fast and doesn’t require complex querying.
Common key-value databases: Redis, Memcached
- Graph Databases
Graph Databases is a graph database which is specialised and has the single purpose of creating and manipulating graphs. Graphs contain nodes, edges, and properties, all of which are used to represent and store data in a way that relational databases are not equipped to do.
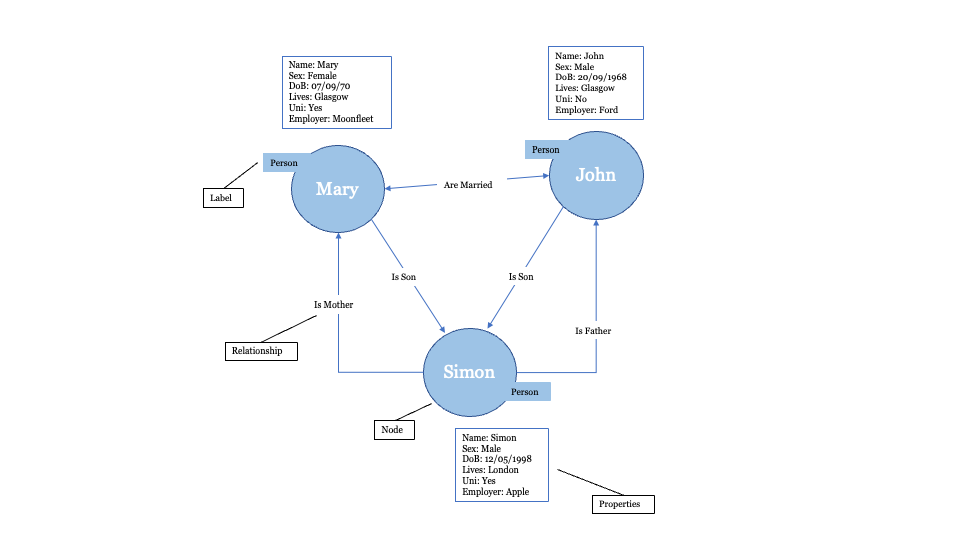
Common graph databases: Neo4j, InfiniteGraph
Relational vs. Document Databases
As you probably figured out by now, there is no right answer, no ‘one database fits all’. It very much depends on the requirement and / or the data. The most commonly used databases for general purposes are the Relational and Document databases, so let’s compare them.
Advantages of relational databases
-
- They have a simple structure that matches most kinds of data you normally have in a program.
- They use SQL, which is commonly used and inherently supports JOIN operations.
- All the records are saved on one machine, and relations between records are used as pointers, this means you can update a record once and all its related records will update immediately.
- Relational Databases also support atomic transactions.
Atomic Transactionsare associated with Database operations where a set of actions must ALL complete or else NONE of them complete. For example, You want to transfer £100 from Alice to Andy. I want to perform 3 actions: decrease Alice’s balance by £100, increase Andy’s balance by £100 and record the transaction. All these actions need to happen successfully, or none at all.
Disadvantages of relational databases
-
- Since each query is done in a table — the time to execute depends on the size of the table. This is a significant limitation that requires the tables to be kept relatively small and must perform optimisations such as archiving within the database to scale.
- Scaling requires additional computing power to the machine that holds the database. This can cause problems since there is a limit to how far hardware can be ungraded before it needs replacing, this requires both downtime and expenditure.
- Relational databases do not support Object Orientated Programming based objects, making even representing simple lists very complicated. Object-oriented programming(OOP) is a programming paradigm based on the concept of “objects”, which can contain data and code. The data is in the form of fields and the code is in the form of procedures.
Advantages of document databases
-
- They allow you to keep objects with different structures, for examples images of documents.
- They can represent almost all data structures including OOP (Object Orientated Programming) based objects, lists, and dictionaries using JSON.
- Although NoSQL is not schematised by nature, it often supports schema validation, meaning you can define a schema for a collection, the schema won’t be as simple as a table, it will be a JSON schema with specific fields.
- Querying NoSQL is very fast, each record is independent and therefore the query time is independent of the Database’s size and supports multiple queries in parallel.
- In NoSQL, scaling the database can be achieved by adding more machines in the form of parallel processing and distributing your data between them. This allows users to automatically add resources to the database causing any downtime or disruption.
Disadvantages of document databases
-
- Updating the data in a document database can be a slow process since the data can be divided between machines or duplicated across the machines.
- Atomic transactions are not inherently supported. They can be added in code by using verification and revert mechanisms, but since the records may be divided between machines, it cannot be an atomic process and race conditions, (an undesirable situation that occurs when a device or system attempts to perform two or more operations at the same time), can occur.